Introduction to Quantum Computing and Classical Supercomputing
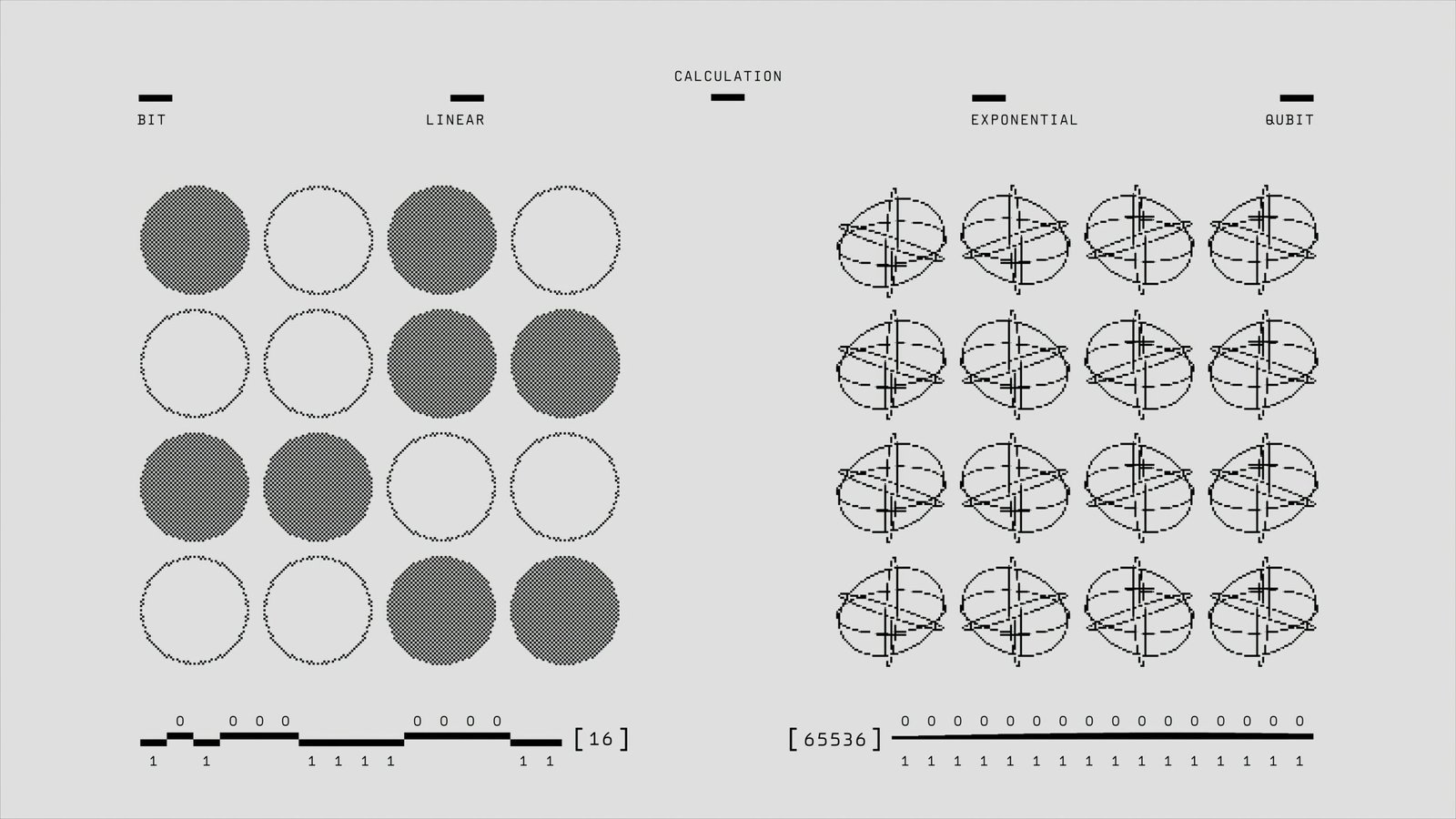
Quantum computing and classical supercomputing represent two significant paradigms in computing technology, each underpinned by distinct principles and mechanisms. Classical supercomputers, which have been the stalwarts of data processing for decades, rely on the well-established framework of bits that operate within the binary system. These bits serve as the basic units of information, existing in one of two states: 0 or 1. By leveraging thousands of interconnected processors, classical supercomputers can perform a vast array of high-performance calculations with remarkable speed. Their utility has been particularly pronounced in fields requiring immense computational power, such as climate modeling, molecular dynamics simulation, and complex financial modeling.
In contrast, quantum computing emerges from the principles of quantum mechanics and fundamentally alters how information is processed. Instead of bits, a quantum computer utilizes quantum bits, or qubits, which exploit the phenomena of superposition and entanglement. This allows qubits to exist in multiple states simultaneously, resulting in a potentially exponential increase in computational capability. The promise of quantum computing lies in its ability to tackle complex problems, such as integer factorization and simulation of quantum systems, which remain intractable for current classical supercomputers.
The significance of these technologies extends beyond mere speed; it is about enhancing the ability to solve problems that were previously unimaginable. In modern applications, from artificial intelligence to cryptography and materials science, the growth of computational power has substantial implications. Understanding the inherent differences in the architectures of quantum computing and classical supercomputing is crucial, as it sets the groundwork for exploring how these technologies might coexist or compete in real-time computing environments and their respective contributions to advancing technology and science.
Tightly Coupled vs Shared Memory Calculations
The distinction between tightly coupled and shared memory architectures is fundamental in the realm of classical supercomputing. In tightly coupled systems, multiple processors or nodes are interconnected in a manner that enables rapid communication and coordination. This configuration is often seen in high-performance computing environments, where tasks require significant collaboration among processor units. By offering low-latency communication, tightly coupled architectures excel in scenarios where computational tasks involve complex exchanges of data, allowing for efficient performance in parallel processing applications.
In contrast, shared memory architectures operate under a different paradigm. Here, multiple processors access a single shared memory space, facilitating the straightforward sharing of data among them. This architecture simplifies programming, as developers can use shared variables without worrying about the intricacies of message passing. However, it can lead to contention issues when multiple processors attempt to access the same memory location concurrently, potentially hindering performance. This type of architecture is particularly beneficial for applications that can leverage threads effectively, such as certain scientific computations and simulations.
The performance implications of these two architectures become apparent when dealing with complex calculations, especially in high-performance clusters. Tightly coupled systems provide continuous communication, making them suitable for simulations requiring close interactions among components, such as fluid dynamics. Conversely, shared memory systems may offer ease of use in applications that involve straightforward data sharing without extensive interdependencies.
Each architecture has its merits and limitations, and the choice between tightly coupled and shared memory calculations ultimately depends on the specific requirements of the computational task at hand. By understanding these distinctions, researchers and developers can better decide on the most suitable architecture for their high-performance computing needs.
Quantum Computing Architectures and Memory Utilization
The architecture of quantum computing is fundamentally different from that of classical supercomputing, primarily due to the unique properties of quantum bits, or qubits. Unlike classical bits, which can occupy a state of either 0 or 1, qubits can exist in a superposition of states, enabling them to perform complex calculations at exceedingly rapid rates. This non-classical behavior allows a quantum computer to process vast amounts of data simultaneously, vastly improving computational efficiency for certain types of problems.
One of the core components of quantum architectures is the concept of entanglement, which facilitates highly complex interconnectedness among qubits. Entangled qubits maintain a state that is dependent on one another, allowing quantum systems to encode and transmit information in ways that classical systems cannot. This leads to the potential for exponential speedup in computational tasks such as cryptography, optimization, and simulating quantum systems, marking a significant advancement over traditional supercomputers.
Memory utilization in quantum computing directly contrasts with the shared memory models typically employed in classical supercomputing. In classical systems, processors share access to a common memory space, which may lead to bottlenecks as multiple processors vie for memory access. On the other hand, quantum computers rely on quantum memory, which is distributed across qubits. This distribution allows individual qubits to maintain their quantum information locally, which helps prevent the latency issues frequently encountered in classical architectures.
Additionally, quantum memory can efficiently perform quantum error correction, which is vital for maintaining the integrity of calculations in quantum computing. As quantum systems are particularly sensitive to environmental disturbances, effective memory management techniques are crucial for the stability and reliability of calculations. Consequently, the architecture of quantum computing and its memory utilization present unique advantages that could revolutionize fields requiring high-throughput data processing.
Real-Time Computing: Hard vs Soft Real-Time Systems
Real-time computing is fundamentally concerned with the timely processing of data and responding to events, categorized into two main types: hard real-time and soft real-time systems. Hard real-time systems are characterized by their strict timing constraints; failure to meet these constraints can result in catastrophic failures or dangerous situations. These systems are commonly employed in critical applications such as avionics, medical devices, and automotive safety systems, where exact timing is crucial. For example, in an aircraft control system, a missed deadline could jeopardize passenger safety, emphasizing the importance of reliability in hard real-time performance.
On the other hand, soft real-time systems permit a degree of flexibility regarding timing constraints. While timely responses are still important, occasional delays might be acceptable without severely compromising system functionality. These systems are prevalent in applications such as multimedia streaming, online gaming, and interactive web applications, where a slight delay may impact user experience but will not lead to catastrophic outcomes. In such scenarios, the performance degradation is often tolerable, allowing for adjustments to be made without significant repercussions.
It is essential to recognize the implications of meeting or missing timing constraints in both hard and soft real-time systems. In hard real-time systems, missing a deadline can lead to system failures and endanger lives, making mission-critical reliability paramount. Conversely, failing to meet deadlines in soft real-time systems may only result in decreased performance or user dissatisfaction. Understanding these distinctions is vital for developers and engineers, as they will dictate system design choices, resource allocation, and resilience measures required to ensure functional integrity across various operating conditions.
Performance Metrics: Speed Up in Real-Time Computing
Evaluating the performance of computing systems, particularly in the context of real-time applications, necessitates an understanding of specific metrics that measure speed and efficiency. Real-time computing can be broadly categorized into hard and soft systems, with each having distinct requirements and performance expectations. Hard real-time systems demand strict deadlines, where failure to perform computations on time can result in critical failures, while soft real-time systems are more lenient, allowing for occasional lapses in timing.
One key metric in assessing real-time computing performance is latency, which indicates the time taken from the initiation of a task to its completion. In both classical supercomputing and quantum computing, minimizing latency is crucial for ensuring efficient processing of real-time data. Moreover, throughput, which refers to the number of processed tasks within a specific timeframe, serves as another vital metric. Improving throughput is essential for applications that require constant data flow, such as streaming services and autonomous vehicles.
Factors affecting speed-up in real-time computations involve hardware capabilities, algorithms employed, and resource management strategies. In classical supercomputing, advancements in parallel processing and the use of graphics processing units (GPUs) significantly enhance performance. Quantum computing, on the other hand, has the potential to outperform classical systems by leveraging quantum bits (qubits) to complete complex calculations more quickly. The unique nature of quantum superposition and entanglement allows for simultaneous exploration of multiple solutions, thereby potentially reducing computation time for certain problems.
To effectively compare these systems, benchmarks such as the Response Time Benchmark and the Real-Time Performance Tool can be utilized. These tools provide a framework for assessing the responsiveness and efficiency of both hard and soft real-time computing systems. By implementing these performance metrics, organizations can determine the most suitable computing architecture for their specific real-time data processing needs.
Edge Computing: An Emerging Paradigm
Edge computing represents a transformative shift in the way data is processed, managed, and analyzed. Unlike traditional cloud computing, where data is transmitted to centralized data centers for processing, edge computing enables data to be processed closer to the source of the data generation. This localized processing is particularly advantageous in scenarios that require real-time computing capabilities, vastly reducing latency and bandwidth use.
At its core, edge computing leverages edge devices, such as IoT (Internet of Things) endpoints, sensors, and gateways, to execute computations directly where data is created. This decentralized approach allows for immediate data processing and faster response times, making it an ideal solution for applications that demand prompt information feedback, such as autonomous vehicles, smart industrial systems, and health-monitoring devices. By efficiently handling data at the edge, organizations can gain insights and reactions that are vital in time-sensitive environments.
In addition, edge computing alleviates some of the pressure on traditional cloud infrastructures. With the proliferation of IoT devices generating massive amounts of data, relying solely on cloud computing can strain network capacities and result in potential bottlenecks. Edge computing addresses this challenge by filtering and aggregating data locally before relaying only the most critical information to the cloud for further analysis or storage. This not only enhances the efficiency of data transfer but also ensures that essential data is acted upon without unnecessary delay.
Furthermore, as security and privacy concerns continue to grow, edge computing minimizes risk by allowing sensitive data to be processed locally rather than sent to distant servers. This localized processing can help organizations comply with data regulations and safeguard users’ sensitive information while still deriving meaningful insights from their data. In essence, edge computing is emerging as a foundational element in the future of computing architectures, complementing classical supercomputing and quantum computing with its real-time processing capabilities.
Advantages of Local Edge Computing Over Cloud Computing
Local edge computing has emerged as a transformative approach in the landscape of data processing, offering distinct advantages over traditional cloud computing paradigms. One of the most significant benefits is reduced latency. When computation occurs closer to the source of data, such as IoT devices or user endpoints, the time taken for data exchange is considerably minimized. This proximity enables near-instantaneous responses, which is crucial for applications that require real-time processing, such as autonomous vehicles or smart manufacturing systems.
Another critical advantage of local edge computing is enhanced bandwidth utilization. In scenarios where vast volumes of data are generated, sending all that information to a centralized cloud for processing can lead to network congestion and increased operational costs. By processing data at the edge, only relevant information is transmitted to the cloud, significantly alleviating bandwidth usage and optimizing network resources. This is particularly beneficial in environments where bandwidth costs are high or where connectivity may be unstable.
Moreover, local edge computing enables better data security and privacy. When sensitive information is processed locally, there is a reduced risk of exposure during data transmission to the cloud. Organizations can maintain greater control over their data, which is vital for compliance with regulations such as GDPR. By keeping sensitive data within localized systems, companies can mitigate potential risks associated with centralized data storage.
Additionally, local edge computing offers enhanced resilience. By not relying solely on cloud infrastructure, which may become vulnerable to outages or downtime, edge computing systems can continue functioning independently. This robustness plays a crucial role in industries that require continuous operation and high availability. Overall, these advantages illustrate the growing importance of local edge computing as a viable alternative to traditional cloud services, especially in real-time applications and environments requiring swift data processing capabilities.
Comparative Analysis: Quantum vs Classical Efficiency in Edge Computing
The landscape of computing technology has undergone significant evolution, particularly with the emergence of quantum computing as a formidable contender against classical supercomputing. In the context of edge computing, understanding the efficiency of these two paradigms is essential for optimizing performance and resource allocation. While classical supercomputers excel in handling vast quantities of structured data through established algorithms, quantum computing presents an alternative that leverages quantum bits, or qubits, to potentially solve complex problems more efficiently.
One scenario where classical supercomputing may outperform quantum computing is in tasks that require high precision and established algorithms, such as numerical simulations and data analytics. Classical supercomputers are designed to manage large-scale computations with reliability, making them ideal for applications in weather forecasting and financial modeling, where the accuracy of results is paramount. Their ability to perform a large number of calculations in parallel remains a significant advantage in edge computing, especially for organizations that rely on real-time data processing.
Nevertheless, the realization of quantum computing’s full potential is still contingent upon overcoming technical challenges such as qubit coherence and error correction. Ongoing research and development are critical to harnessing quantum efficiency in edge computing effectively. Each technology possesses its own strengths and ideal use cases, emphasizing the importance of evaluating specific requirements before deciding between classical and quantum computing solutions for edge environments.
Conclusion: The Future of Computing Technologies
As we reflect on the key distinctions between quantum computing and classical supercomputing, it becomes evident that both technologies possess unique strengths that cater to different computational needs. Quantum computing revolutionizes information processing through the principles of superposition and entanglement, enabling it to solve certain complex problems exponentially faster than classical supercomputers. However, classical supercomputers, built on established algorithms and architectures, continue to dominate in various applications, especially where reliability and absolute precision are paramount.
In real-time computing contexts, the immediate execution of tasks is crucial. Classical supercomputers excel in scenarios where tasks require predictable outcomes and operational stability, making them indispensable for applications like weather forecasting and financial modeling. Conversely, as quantum technologies mature, they promise significant advancements in complex simulations and optimizations that were previously unattainable, potentially transforming fields such as drug discovery and material science.
The future of computing technologies lies in the integration of these systems. Hybrid models that leverage the power of classical supercomputing alongside quantum computing can lead to breakthroughs by enabling researchers and businesses to tackle multifaceted challenges. Moreover, advancements in quantum error correction and coherence times will gradually improve the feasibility of practical quantum solutions in the coming years.
It is important to monitor and foster collaborations between academic, industrial, and governmental entities to further explore the implications of both quantum and classical computing. As the landscape evolves, the synergy between these two paradigm-shifting technologies will shape how computational power is harnessed in numerous sectors, promising innovations that we have yet to fully comprehend.